信用评级知识(十七) 浅谈财务粉饰及财务造假(下)
--如何识别财务粉饰及造假
一、前言在“浅谈财务粉饰及财务造假(一)”中,我们主要讨论了财务粉饰及造假的动机和手段,面对纷繁复杂的财务粉饰及财务造假,通常有哪些方法能帮助我们识别呢?
二、财务粉饰及造假的识别方法财务粉饰及造假的识别本质上属于财务分析的一部分。有效的财务分析不仅仅要充分利用会计数据和信息,而且要善于运用非会计数据和信息,比如企业所处的经营和竞争环境,以及自身的经营战略等。财务粉饰及造假的识别,更是应该充分利用财务和非财务两方面的信息,即将财务数据与企业及所处环境基本面的分析紧密结合在一起。
识别财务粉饰及造假的具体方法繁多,从信用风险分析的角度,这些方法大体可以分为经营反推法、同业比较法和趋势分析法三大类。
(一)经营反推法经营反推法的基本原理是,企业的财务报表必然是其经营结果的反映和表现。如果企业的实际经营与财务报表所展示的结果不一样,则说明财务报表存在虚假的可能。常用的经营反推法如下:
1、经营阶段及战略与财务表现相冲突
首先,不同发展阶段的企业具有不同的财务特征,企业财务表现应该与其所处行业及自身的发展阶段相匹配。比如,处于成长期的企业,一方面其技术研发及销售网络建设等方面均处于大规模投入期,另一方面伴随着技术及市场的投入,销售收入也处于快速的增长中。因此,这类企业的财务表现往往是收入快速增长,但成本上升也很快,处于增收不增利的阶段。即使毛利率由于规模效益的逐步显现而能够维持稳定,期间费用的快速增长及资产规模的快速扩大也会使得其资产报酬率下降。如果企业的财务表现与其上述所处发展阶段不相匹配,并且没有其他合理的理由可以解释,则要怀疑其财务报表的真实性。
其次,实施不同经营战略的企业应该具有不同的财务特征。比如,实施成本领先战略的企业,并且确实具有低成本优势,比如原材料和人力成本低,但财务表现的财务成本却明显与此不相匹配,则要怀疑企业是否存在隐瞒或者转移利润的可能性。
2、销售等经营数据与收入及利润的表现不一致
企业所披露的销售数量、单位价格及成本等数据应该与其销售收入及利润的表现大体相一致,至少不应该长期背离。比如,如果根据企业所披露的销售相关数据所推算的销售收入、毛利率等指标与财务报表存在无法合理解释的差距,这应该怀疑其财务报表的合理。
同时,企业销售对象及主要客户的销售量或销售额应该符合基本的逻辑。
3、投资及税收等支出等与财务报表不匹配
企业无论是固定资产投资还是对外股权投资,都应该在财务报表体现出来。比如,企业经常公告固定资产投资项目,构建固定资产所支付的资金也非常巨大,但固定资产或在建工程不见同步增长,则表明企业存在转移资金或者表外资产的可能性。
同理,财务报表所体现出来的税收等支出也应该与当地的税收政策及企业实际的经营状况相匹配。税收支出异常高企或异常低,都可能表明企业收入或者利润存在隐瞒或虚增的可能性。但必须指出的是,税收的实际征收与会计处理之间存在差异,运用该方法的时候要谨慎,不能简单因为税收存在差异就怀疑企业收入虚假。
4、资产构成或质量与财务报表表现不一致
一般而言,企业所在行业的特性决定了企业的资产构成,而资产构成及业务特性又基本决定了企业的财务表现。比如,航空公司属于典型的固定资产密集型企业,固定资产的周转率在很大程度上决定了企业的资产报酬率,如果一家航空公司固定资产占比过低,并且固定资产周转率及盈利与其披露的客运量及客座率不匹配,则要怀疑其财务报表的真实性。
另一方面,资产的质量也决定了盈利的表现。比如一个厂房及设备明显老旧的企业,其固定资产的陈新率应该较低,维护费用相对较高,生产效率相对较低,在其他条件大体相同的情况下,其毛利率也应该相对较低。如果不是如此,并且无法获得合理解释,就要怀疑企业是否虚增了利润。
5、资本或资金来源与实际控制人及财务表现背离
天底下没有免费的午餐,如果企业主要资本金或资金来源与实际控制人在财务方面没有密切的关联,则往往存在问题。另一方面,如果企业大规模使用高成本资金,而利息支出(包括经营性和资本性的利息)却异常低,则要怀疑企业是否在通过特殊手段在虚增利润,或者通过其他手段给予了资金提供方补偿。
事实上,经营反推法还有很多,并且往往需要综合运用多种手段,并且需要其他手段配合和验证,才能识别并确认企业是否存在财务造假或粉饰。
(二)同业比较法同业比较法是通过与同业相同指标的对比和分析,从中发现不合理因素并识别可能存在的财务虚假行为。其背后的基本逻辑是,同行业企业所处的经营环境大体相当,经营结果即使有差异也应该能够得到合理解释。当企业与同行的财务表现存在无法合理解释的因素时,则其出现虚假的可能性较大。
同业比较的要点有二,其一是同业比较对象的选择,其二是比较指标的选择。同业比较对象应该选择产品(或服务)及经营环境大体相同,彼此具有竞争关系的企业。
比较指标选择的原则是应该具有可比性,即这些指标计量的基准应该基本相同,并且应该尽可能剔除税收等非自身因素的影响,只反映企业自身经营或竞争能力。比如毛利率是比较好的指标,因为绝大多数企业对毛利率的计量基准是一致的,并且各地税收政策方面的差异不会对该指标的计量产生影响。
根据同业比较来质疑财务虚假比较有名的案例当属前段时间闹得沸沸扬扬的山东宏桥(1378.HK)。在爱默生的做空报告中,分别选取焦作万方(000612.SZ)、河南神火(000993.SZ)、中孚实业(600595.SH)、南山铝业(600219.SH)和新能泰山(000720.SZ)、华能电力(0902.HK)、华润电力(0836.HK)、中国电力(2380.HK)作为利润率和发电成本的比较对象。但是拿焦作万方、华润电力等国企,与行业内成本控制和运营管理都极具效率的企业来对比,其实不具有很好的可比性。
需要指出的是,同业比较须与行业及企业的基本面分析紧密结合,有效区分异常因素是源于基本面还是财务操纵,否则同业比较很难发挥真正作用。
(三)趋势分析法趋势分析法主要是通过观察和比较各种财务指标的趋势性变化,从中发现异常并识别财务虚假行为。常用的趋势分析法如下:
1、相同指标的变化趋势分析
一般而言,企业的财务指标总是随其所处的经营环境、所处发展阶段及经营策略的变化而呈现规律性的变化。比较典型的指标有毛利率、期间费用率、存货减值率和总资产报酬率等。如果这些指标的波动或者变化趋势明显异常,超出了行业或自身经营的变化范围,则要怀疑企业财务是否存在虚假。
2、关联指标的变化趋势分析
企业的财务指标大多相互关联,相互影响。比如上述毛利率、期间费用率、资产周转率等指标与总资产报酬率都存在密切关系,如果这些指标长期相互背离,需要引起高度注意,分析其出现背离的原因是否合理。
同理,业务收入、应收应付等指标与现金流指标密切相关,如果企业的业务收入及利润与经营性现金流相关指标长期背离,则说明企业存在虚假销售的可能性,要关注企业应收账款是否计提了足够坏账准备等。
三、利用模型快速识别财务虚假前文的识别财务粉饰及造假的方法,更多是基于经验或者专业基础上的具体案例分析,不适合快速、大批量地对财务报表的虚假情况做出评判。在实际投研之中,也不太可能要求分析师对每一个投资对象是否存在财务虚假进行详细的分析与研究。此时,构造科学的财务虚假识别模型,对于帮助分析师在日常研究中,高效、准确地判别财务报表虚假程度,帮助机构投资者准确评估投资标的风险、规避“地雷”具有重要意义。
在上述三种识别财务粉饰及造假的方法中,经验反推和同业比较必须大量使用与分析对象相关的特定信息,很难将这些信息抽象化并构建可靠、高效的量化模型。故,构建量化财务虚假识别模型的理论基础大多基于趋势分析法,即在建模指标的选择中,优先选择与趋势分析相关的指标,并通过模拟异常趋势指标来识别财务报表虚假可能性的高低。
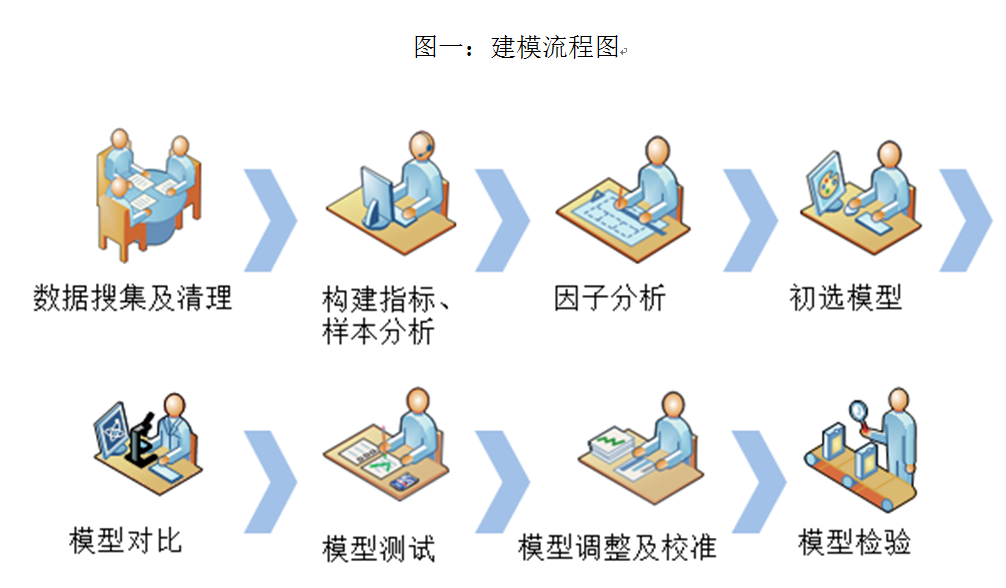
1、建模流程及方法概述
严谨的建模流程和科学可行的方法是确保模型可用的基础。建模流程从样本数据的收集和整理开始,然后是模型指标的构建和筛选,主要是构建备选指标库并通过相关分析、单因素分析等多种统计方法对指标进行筛选,利用筛选过的指标构建多个备选模型,并通过随机样本集对模型进行稳定性和准确性的测试,选择最优的模型并对指标权重进行人工干预,最后对模型分别进行样本内外的测试,以保证模型的普遍适用性。
在方法上,由于因变量为“是”“否”造假的分类变量,一般采用两水平的logistic回归建模,根据财务数据预测公司财务虚假的概率,并根据cutoff点确定是否造假。但在实际的应用过程中,两水平的分类往往过于粗略,所以我们根据概率大小和样本的占比将等级划分为5类,帮助分析师更为清晰的了解财务虚假的情况。
2、建模样本来源及概要
构建可靠、可用的财务虚假识别模型的根本在于有合适的建模样本。对于机构投资而言,建模样本的基本要求有三:其一是必须是大型企业,最好是上市或发债的大型企业;二是数据必须公开可得而且权威可靠;三是数据必须完整而且有足够的样本量。
根据以上原则,我们选取因“虚列资产”“虚构利润”等被监管机构明确处罚的上市公司作为财务造假样本。与虚假样本有明确的标准不同,“正常”样本的选择需要更加谨慎,既要与虚假样本有一定区分度,又不能要求过高,从而避免虚假样本与正常样本有“显著”的区别,导致模型过拟合以至在实际应用中的适用性不高。基于以上原则,我们会制定相应规则,如“权威事务所审计且连续三年出具‘标准无保留意见’”、“连续三年无会计事务所变更”、“公司连续三年无行业变更和重大变化”、“从未出现过ST”等条件去筛选财务状况相对良好的企业作为正常样本,并对样本进行去重和提取财务数据等基础性工作,保证建模数据的质量。
根据上述筛选规则,最后得到105条虚假样本数据和237条正常样本数据,样本整体分布在2005-2015年,其中2010年及以后的样本占比70%以上,样本所属行业(wind一级行业)主要以工业(占比36.5%)、可选消费(占比13.7%)和日常消费行业(占比10.2%)居多。
3、样本指标构建及筛选
获得可靠的样本数据以后,就可以构建样本指标并进行必要分析。一般而言,可以根据专家经验及上述提及财务虚假识别方法论,尽可能多地列出能够识别财务虚假的指标,常见的指标比如归属于母公司所有者权益的变化率、毛利率的变化率、现金流/营业收入的变化率等。
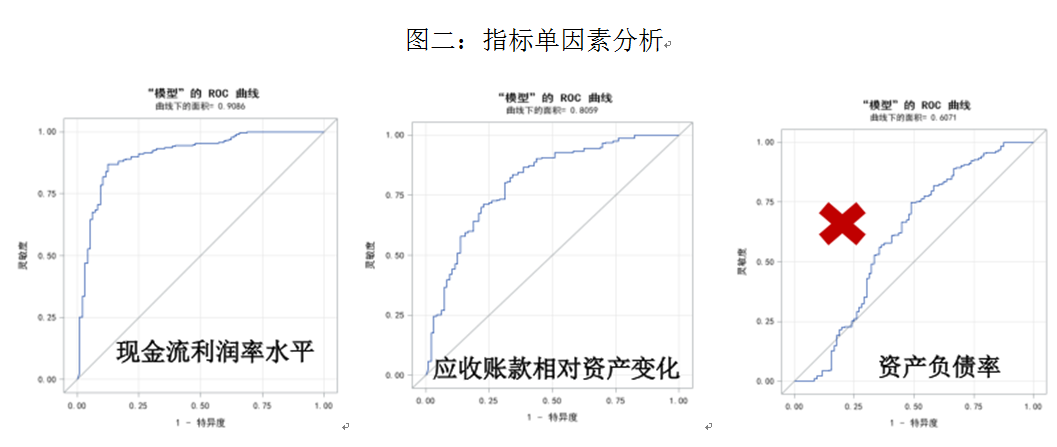
通过对指标进行非参数检验、相关分析和单因素分析,剔除不能明显区分造假与正常样本和效果较差的指标(如图一的资产负债率),并对明显存在共线性的指标进行筛选,减小多重共线性对于模型指标估计值的影响,通过上述步骤筛选出初步的建模指标,并对样本进行异常处理,减少异常值对于模型准确性和稳定性的影响,最后借助建模软件及经验的干预,在保证模型统计学和经济学意义的前提下,反复调整指标,得到多个备选模型。
4、模型选择及模型稳健性测试
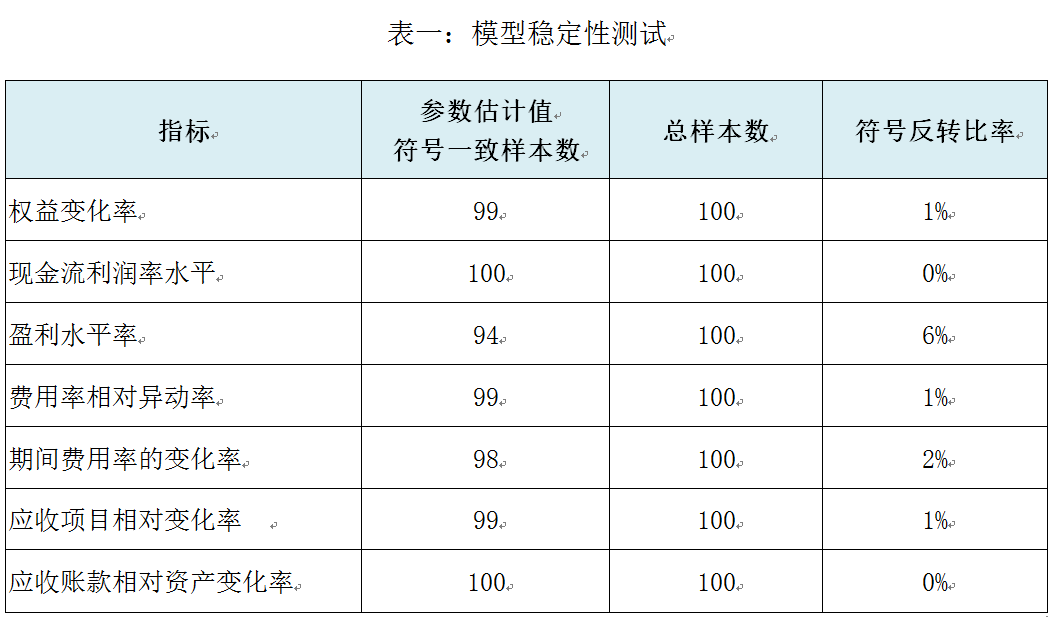
为了对比备选模型之间的效果,利用随机样本对备选模型进行准确性测试,通过比较模型的拟合度和指标估计值,选择表现最优的模型,同时为了测试模型对于不同样本以及在今后实际应用过程中的适用性,我们将通过随机样本对模型的稳定性进行检验,观察估计值的符号反转情况(如表一,指标符号几乎并未反转),且在准确性没有明显降低的前提下,对指标权重进行人工干预和调整以保证模型的均衡性和合理性,从而得到最终模型。
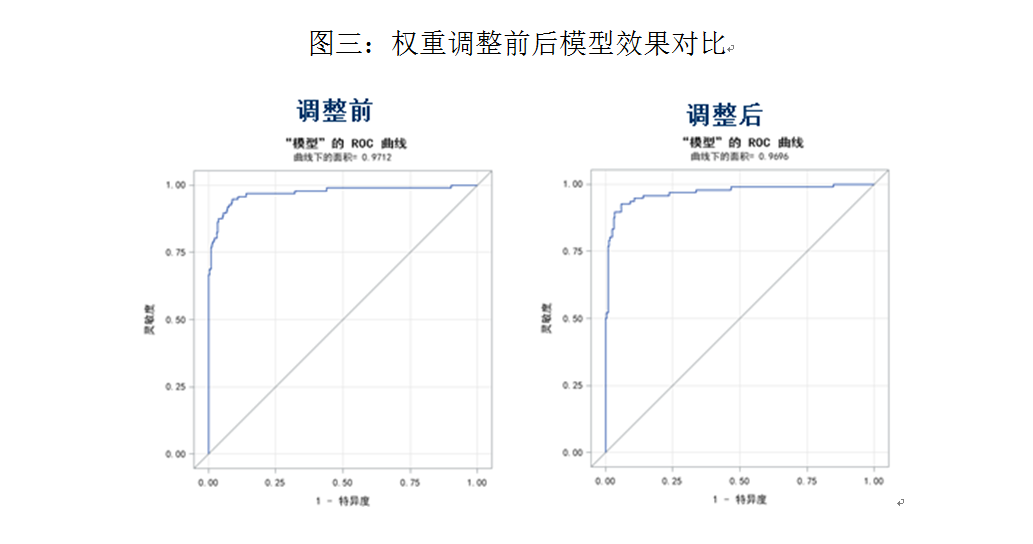
5、模型结果测试及应用案例
为了保证准确性和普遍适用性,模型的测试和验证步骤必不可少。财务虚假识别模型样本内的准确度可达93.4%(其中第一类错误5.91%,第二类错误7.29%),整体效果较好。同时,对于市场上最新披露的财务造假公司(如乐视网、新査矿业、神马股份、欣泰电气等)也有很好的识别效果。