

从某制药企业“会计差错”看财务虚假识别模型的应用
更新时间:2019年5月5日
近日某A股上市公司(以下简称“XM药业”)公告其2018年度前期会计差错更正专项说明,由于关键会计科目“差错”而对2017年财务报表进行了远超市场预期的巨额追溯调整,引发市场一片哗然、愤慨。
引发市场哗然、愤慨的不仅仅是高达数十亿元的收入及成本费用的差错而导致利润和经营性现金流大幅缩水,更重要的是因所谓“核算账户资金时存在错误”导致2017年年末货币资金多计近300亿元,因所谓“会计处理错误”导致存货少记近200亿元。
一直以来,XM药业一方面以其良好的账面盈利表现和稳健的账面资产负债表而广获追捧,其中不乏知名机构投资者和专业证券分析师。自2001年上市以来,XM药业营业收入从不足4亿元上升了超过50倍至2018年的近200亿元,年均复合增长率超过25%;税后净利润则从2001年年末的不足0.3亿元,到2016年创记录的33亿元,增长超过110倍。2001至2016年的15年间,XM药业平均净资产收益率和总资产报酬率分别高达13.5%和12.2%,账面盈利表现不可谓不好。
另一方面,XM药业因其不合常规的大存大贷、远逊盈利的现金流,以及其他有悖于常规的会计处理广受市场质疑。自2006年起,直至会计差错调整前的2017年,XM药业年均持有货币资金占总资产的比重接近40%,约相当于同期短期有息债务的2.4倍。其中,会计差错调整前的2017年年末,其账面货币资金高达341.5亿元,约占总资产的50%,约相当于同期末短期有息债务和总有息债务的1.8倍和1.2倍。这种大量持有货币资金,显示资金宽裕,有大量负债尤其是短期负债的大存大贷,明显不符合商业常规。
自XM药业上市的2001年至2017年(会计差错调整前),其年均经营性现金流净额仅仅相当于同期净利润的52%。2017年和2018年经会计差错调整后,XM药业经营性现金流分别为净流出48.4亿元和31.9亿元。以此为基础计算,自2001年上市以来,XM药业虽然总计实现了约180亿元账面税后利润,但经营性净现金流却净流出约1.5亿元。这意味着,XM药业上市以来,虽然账面盈利表现堪称完美,但并未实现经营性现金流的净流入。所谓利润即使有,也不过账面财富而已。
就是在这种热烈的追捧和广泛的质疑之中,XM制药的股价自上市以来直至2018年债务危机爆发前,上涨了近100倍。堪称完美的账面资产负债表和盈利表,再加上远超财务表现的股票价格走势,即使是原本持怀疑态度的老司机也难免不受外界影响而动摇,原本应该专业、保守的投资者也难免不受诱惑而放松警惕。
事实上,XM药业自上市以来,其财务表现(CAI WU CAO ZONG)是如此之完美,尤其是2006年至2016年财务表现尤其完美的十年间,常规的量化财务虚假识别模型很难捕获其财务虚假。
施久开发的财务虚假识别模型显示,自2001年上市以来,XM药业除上市之初的2001年和2002年,2006年以及2017年和2018年财务报表的虚假可能性为中等及极大以外,其他年份财务的虚假可能性都极小。如果仅仅截取2003年至2016年财务报表,XM药业可以说完美地骗过了施久的财务虚假识别模型,若是XM药业这些年份的财务报表也如2017年那样存在大量“会计差错”的话。
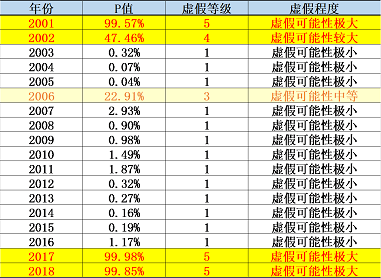
显而易见,虽然XM药业2003年至2016年的财务报表是否存在重大“会计差错”抑或“重大财务操纵、虚假”仍有待权威机构的调查和认定。但就常识而言,这些财务报表大概率并不真实,有重大财务粉饰甚至虚假的可能性极大。如果真如此,是否说明施久的财务虚假识别模型不够准确或者无法有效识别财务虚假呢?
答案并非完全如此。从量化模型开发的角度而言,模型首先必须建立在对专业经验的拟合基础之上。具体到财务虚假识别而言,其方法大体可以分为经营反推法、同业比较法和趋势分析法三大类(详见:《如何识别财务粉饰及造假》)。其中,经验反推和同业比较必须大量使用与分析对象相关的特定信息,很难将这些信息抽象化并构建可靠、高效的量化模型,而只能基于趋势分析法。即:在建模指标的选择中,优先选择与趋势分析相关的指标,并通过模拟异常趋势指标来识别财务报表虚假可能性的高低。
施久的财务虚假识别模型就是基于趋势分析这一基本方法。这意味着,对于一个持续进行财务操纵的公司而言,完全可以掩盖其在趋势上的异常并显得较为合理,从而导致模型难以捕捉到“异常”。但这种财务的操纵,在其操纵或造假之初,或者无法继续操纵而必须回归“正常”时,其财务报表必然会出现异常,这种异常往往易于被模型捕获。XM药业财务报表的虚假等级,在这一点上有清晰的显现。
上市之初的2001和2002年,XM药业财务报表表现极为异常,财务虚假等级均为风险极高的4-5级,此后总体上延续一贯的操纵或虚假,财务报表表现相对“平稳”,模型无法识别受到持续操控的“异常趋势”,财务虚假等级总体为风险极低的1级,直至2017年XM药业受到监管机构调查,原有的财务虚操纵无法继续而必须进行某种程度的回归“正常”,即立刻被模型捕获,财务虚假等级为风险最高的5级。
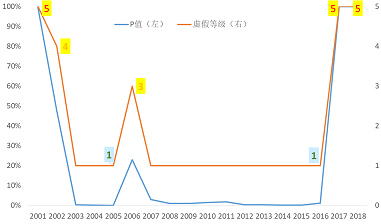
注:虚假等级含义:1表示虚假可能性极小, 2 表示虚假可能性较小,3表示虚假可能性中等,4表示虚假可能性较大,5表示虚假可能性极大。
除了上述模型开发背后的基本逻辑所隐含的不适应场景,从模型开发及应用的角度而言,凡基于统计的量化模型,必然存在第一类错误和第二类错误。完美识别财务虚假的量化模型不仅不可能存在,即使存在,其在实际应用中也必定是不可靠的。毕竟任何量化模型,都只能适合大样本的处理,只能够保证验证样本作为一个整体与建模样本是无偏的,确保错误率处于可接受的范畴,并不能保证每个被验证样本都是准确无偏的。
不仅没有完美的模型,而且只有合适的模型加上正确的运用才能真正发挥模型的作用。模型不合适不可能发挥效用,有适合的模型不用或者不适当地运用也不可能发挥效用。
最后,具体到类似施久这样的财务虚假识别模型的应用而言,正如XM药业的报表识别结果所显示的:一方面,要高度重视其在初始阶段的财务报表风险,警惕其持续操纵可能对模型识别结果造成的扭曲。既不要轻易忽视模型在初始阶段的异常信号,放松警惕,更不要轻易相信某几个年度 “良好”的模型结果,它们很可能仅仅是持续、长久操纵后的“虚假”表现。另一方面,要充分认识到,模型不是万能的,不可能做到天气预报般准确,更不可能保证每个财务虚假识别结果都可靠,不可忽视专业分析与经验判断对模型结果的校正作用。事实上,只有将模型与人的专业判断完美结合,才能在财务虚假识别方面起到事半功倍的效果。